Consider a coin toss.
We “know” that the probability of getting a heads (and tails) is 
In the language of probability, a coin toss is a Bernoulli random variable with parameter 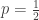
The probability of a heads (or tails) is very simple. Let 



Then suppose the probability of getting a heads or tails is no longer symmetric (or fair), i.e we have 

It seems that we are finished.
Actually we have seen everything from a frequentist (statistician’s) view. A Bayesian statistician looks at this very differently. It is the difference between someone who views probability with objectivity and someone who views probability with subjectivity.
How do we know the probability of getting heads is 
Instead of accepting the probability mass function as it is, we attach another probability to it: the probability of the probability of getting a heads, say 
The answers the question of why we have to assume the probability of getting a heads is
We no longer do. We also no longer assume it is the probability

What value can
Then the random variable
We present the connection between this inference and our usual (frequentist) inference.
Distribution of
Assume the probability of the probability of getting a heads is equal to one. This means it is the probability of heads being equal to 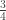
We are assuming that the probability of getting heads follows the unitary continuous uniform distribution. We have

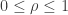
The mass function is just as before. With no inference, we have the same Bernoulli distribution. Challenge: What happens as we change the probability distribution of 




 Posted by AH
Posted by AH 